fMRI Age Prediction Pipeline
This project predicts participant age from resting-state fMRI connectivity data. The pipeline includes preprocessing, PCA-based dimensionality reduction, and Ridge regression modeling.
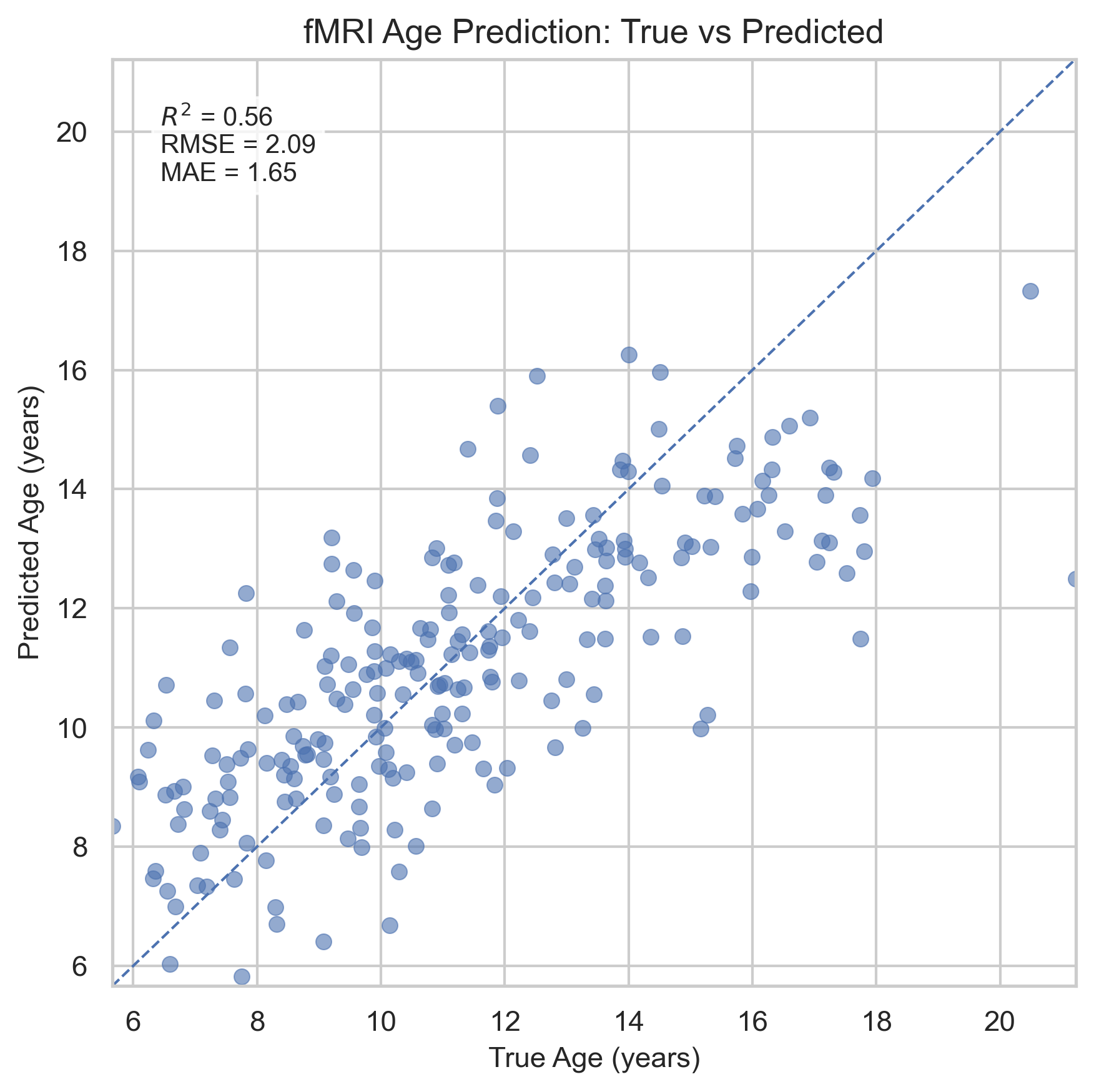
Model Performance
- R² Score: 0.56
- RMSE: 2.09 years
- MAE: 1.65 years
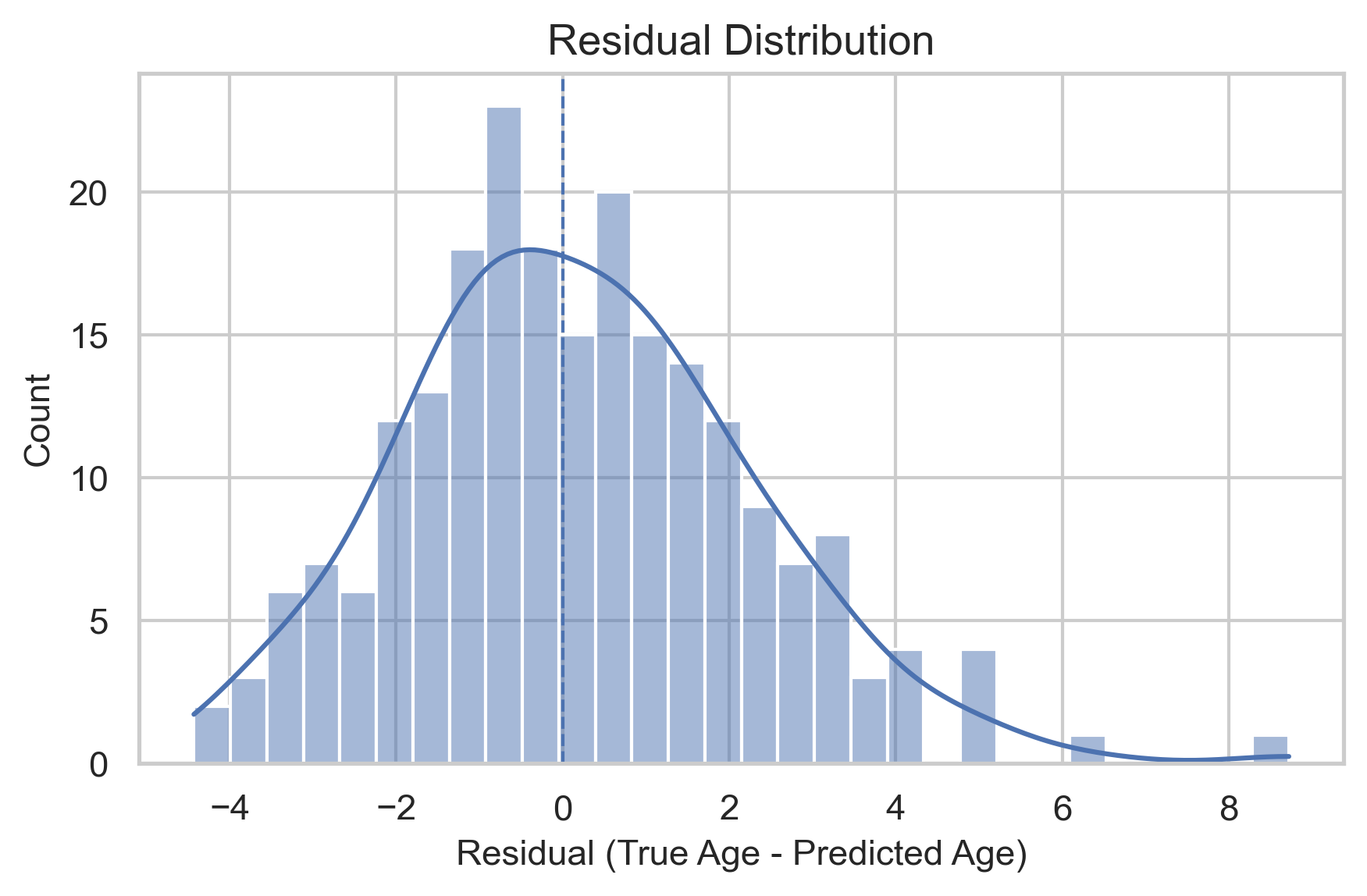
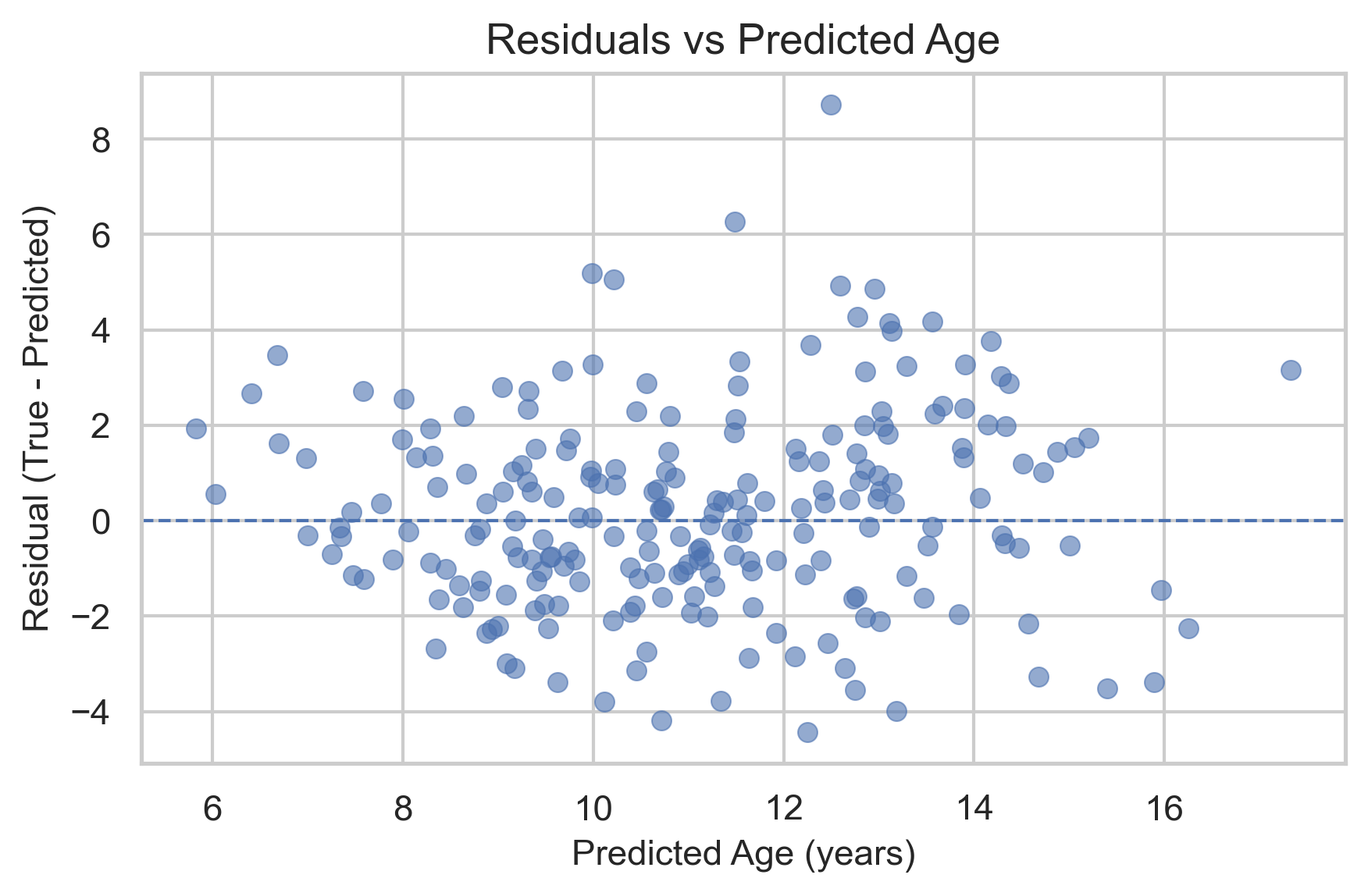
Visual Results
Below are plots from the trained model, showing predicted vs actual ages and residual analysis.
Pipeline Overview
Each subject has a 200×200 functional connectivity matrix (Schaefer2018 atlas). I extract the upper triangle of this matrix into a 19,900-dimensional feature vector.
I join these brain features with participant metadata and use age as the regression target.
I standardize the features and apply PCA to reduce 19,900 dimensions down to 100 principal components, keeping most of the variance while reducing noise and overfitting.
A Ridge regression model is trained on the PCA components with a held-out validation split. Performance is measured using R², RMSE, and MAE on unseen data.
Code Excerpt (Python)
Below is a simplified version of the core training loop: loading connectivity matrices, reducing dimensionality, and fitting a Ridge regression model.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import Ridge
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
# X: flattened connectivity features, y: participant age
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# PCA for dimensionality reduction
pca = PCA(n_components=100, random_state=42)
X_train_pca = pca.fit_transform(X_train_scaled)
X_val_pca = pca.transform(X_val_scaled)
# Ridge regression model
model = Ridge(alpha=1.0, random_state=42)
model.fit(X_train_pca, y_train)
# Evaluation
y_pred = model.predict(X_val_pca)
r2 = r2_score(y_val, y_pred)
rmse = mean_squared_error(y_val, y_pred, squared=False)
mae = mean_absolute_error(y_val, y_pred)
print("R²:", r2, "RMSE:", rmse, "MAE:", mae)